Marking groups
As data are imported in ATHENA, they are listed in the Data
groups list. Each entry in the list includes the name of the data set, the
text of which acts something like a hyperlink in that clicking on that
text will insert the analysis parameters for that group into the main
window. Each entry also has a little check button which is used
for marking the group. Much of
ATHENA's functionality revolves
around marked groups. For example, the marked groups are the ones
plotted when a purple plotting button is pressed, merging is done on
the set of marked groups and, many of the data processing and data
analysis chores use the marked groups.
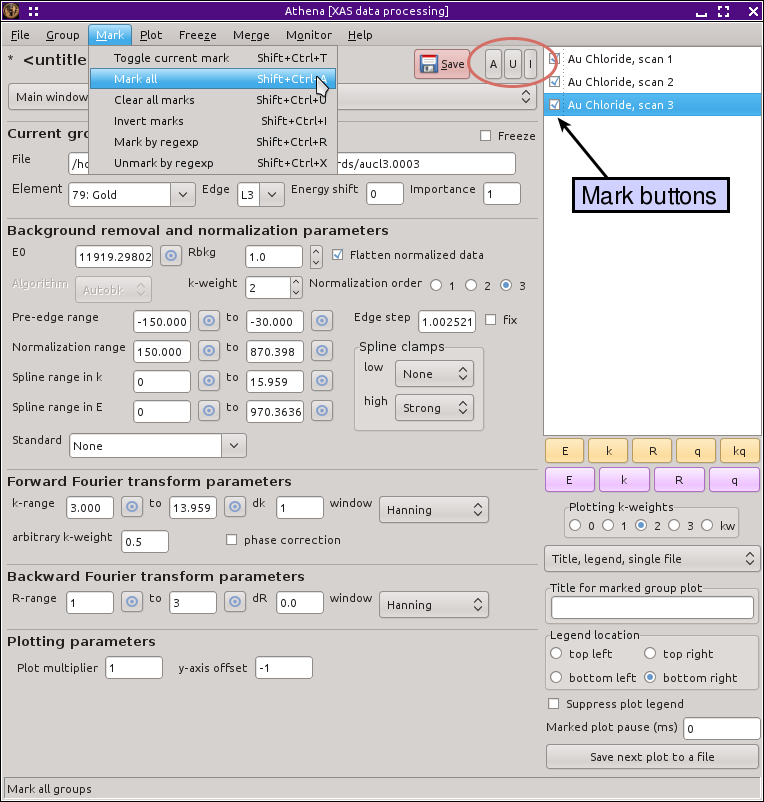
ATHENA offers a number of simple tools for marking or unmarking
groups. These are found in the Mark menu, as shown below, and also
have keyboard bindings. Shift-a marks all
groups, Shift-u unmarks all groups, and
Shift-i inverts the markings such that the
marked groups become unmarked and the unmarked ones become marked.
The three buttons above the group list also serve to make all, mark
none, and invert the marks.
![[Essential topic]](../../images/LightningBolt.png "Essential topic") Using regular expressions to mark groups
Using regular expressions to mark groups
There is one more tool which is considerably more powerful and
flexible. In the Mark menu, this last marking tool it is called
Mark regex and it is bound to
Shift-r.
So, what does regex mean?
Regex is short for regular expression,
which is a somewhat formal way
of saying “pattern matching”. When you “mark regex”, you will be
prompted for a string in the echo area at the bottom of the ATHENA
window. This prompt is exactly like the one used
to rename groups. This string is compared to the names of all the groups in
the Data groups list. Those which match the string become marked and
those which fail to match become unmarked. Let me give you some
examples. In a project file containing various vanadium standards, the
Data groups list includes
These represent the various oxidation states of vanadium. The last
item is an unknown sample which can be interpreted as a linear
combination of the other five samples. There are two scans of each
sample, as indicated by the .1 and
.2.
To make plots of arbitrary combinations of spectra, you can
click the appropriate mark buttons on and off. Using regular
expression marking is quicker and easier. I'll start with a couple
simple examples. If you want to mark only the vanadium foil spectra,
hit Shift-r and then enter
foil. To mark the V2O3 and V2O5, but none of the others,
hit Shift-r and enter V2.
In fact, you get to use the entire power of perl's regular expression
language (see
the regular expression documentation at CPAN
for all the details). This means you can use
metacharacters -- symbols which
represent conceptual aspects of strings. Here are a few examples:
To mark only the V2O3 and VO2 data:
O[23]. That tells
ATHENA to mark the groups whose names have the
letter O followed by either 2 or 3.
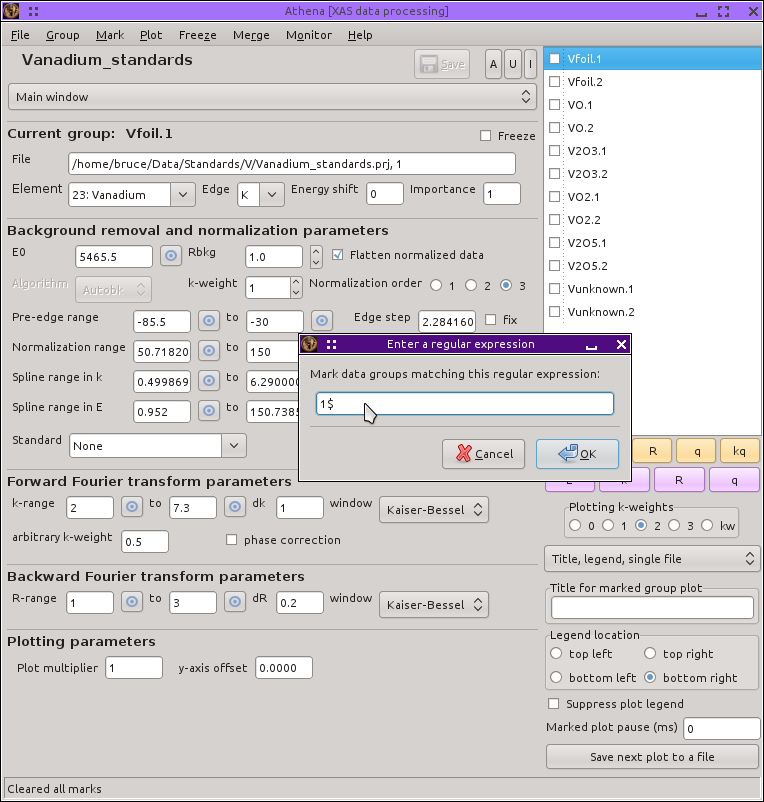
To mark only the first scans of each sample:
1$. The
$ metacharacter represents the end of
a word, thus this regular expression matches all groups whose
name ends in the number 1.
To mark only the foil and unknown data:
foil|unknown. The
|
metacharacter means “or”, so this regular expression matches the
groups with foil or unknown in the name. Actually this regular
expression could have been much shorter, both
[fu] and
f|u would have worked in this case, given
this set of group names.
Regular expressions are a large and fascinating topic of study, but
beyond the scope of this document. Check out the link above read Wikipedia's
excellent article on regular expressions
for more information.
Mastering Regular Expressions
by Jeffrey Freidl is a superb book on the subject.
Any regular expression that works in perl will work for marking groups
in ATHENA. If you enter an
invalid regular expression, ATHENA will
tell you. Regular expression marking is a wonderful tool, especially
for projects containing very many data sets.
 The regular expression is sent exactly as entered to perl's regular
expression engine. You thus have the
full
power of perl's regular expression engine.
The regular expression is sent exactly as entered to perl's regular
expression engine. You thus have the
full
power of perl's regular expression engine.
If you know what “(?{ code })” means and do something ill-advised with
it, you'll get no sympathy from me!
![[Athena logo]](../../images/pallas_athene_thumb.jpg)