Preprocessing data
Manipulating data as it is imported
There are a number of other operations that ATHENA can perform
on your data as it is imported. These are found in the other tabs on
the bottom left of the column selection dialog. Note that all of
the pre-processing chores discussed here can also be performed on
data after it has been imported. See the
data processing chapter.
for more details.
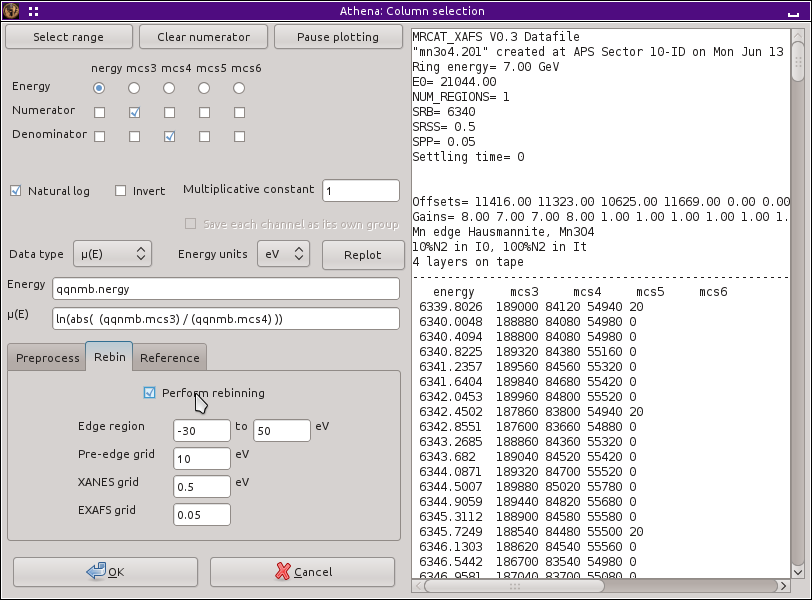
Rebinning quick scan data
Some beamlines offer the option of collecting data as a quick scan.
In that scanning mode, the monochromator is slewed continuous from the
beginning of the scan to the end. The detectors are read continuously
and integrations of the detector signals are stored in intervals. The
length of these intervals and the slewing speed of the monochromator
determine the energy width of each measurement bin. Typically these
measurement parameters are chosen to provide adequate resolution
through the edge -- typically a third or a half of an electron volt.
This results in data that are vastly over-sampled in the EXAFS
region. To improve the statistics in the EXAFS region and to make the
data arrays smaller, it is useful to rebin the data. This process
uses a boxcar averaging to place the evenly spaced quick scan data
onto a typical EXAFS grid. That grid is usually something like 10 eV
in the pre-edge, 0.5 eV through the edge, and 0.05 Å⁻¹
in the EXAFS region.
In
this screenshot,
I have imported some data on a uranyl compound measured in quick scan
mode:
At this stage, ATHENA has not examined the data closely enough
to have guessed what edge you are measuring, so you must specify the
element symbol of the absorbing atom. The remaining numeric
parameters define the grid onto which these data will be rebinned.
The first two numbers define the boundaries of the edge region in
energy, the third defines the size of the grid in the pre-edge, the
fourth defines the size of the grid through the edge, and the last
defines the grid in wavenumber in the EXAFS region.
ATHENA will remember the values of these parameters between data
sets. However, the default is to turn off rebinning for each new data
set. Therefor you must click to the rebinning tab for every data set
you import, and click on the
“Perform rebinning” button. When you
import multiple data sets, though, rebinning will be performed on each
one without intervention according to the normal rules of multiple
data set import.
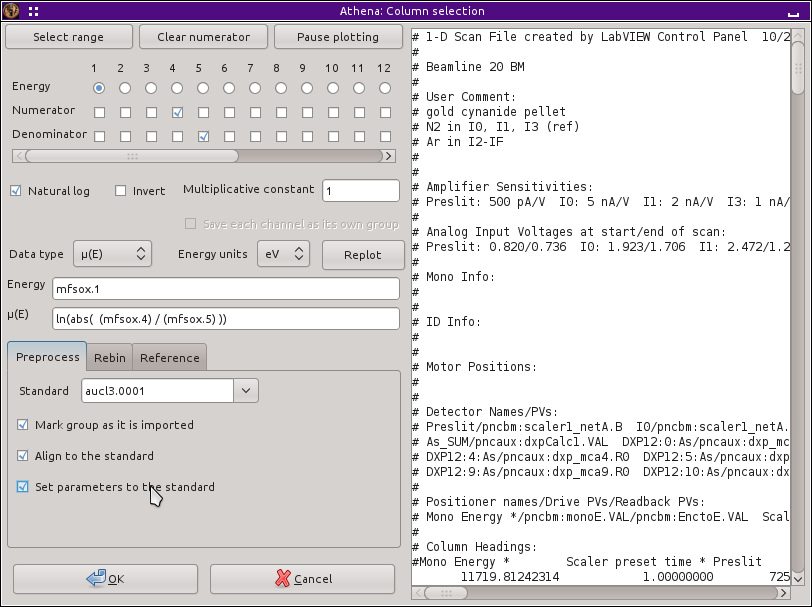
![[Essential topic]](../../images/LightningBolt.png "Essential topic") Other pre-processing chores
Other pre-processing chores
This tab provides controls for a number of other things that can be
done with your data as it is imported. The first one -- marking --
can be performed even on the first data set imported. The other two
require that a standard be specified. The menu at the top of the tab
contains every item from the group list. The one specified in that
menu is the standard.
Here are descriptions of each of the pre-processing chores, seen in
the image above:
-
Mark each data set
-
If this is selected, each data set will be
marked
as it is
imported. Note that the reference spectrum is not marked. Also
note that, unlike the other four pre-processing options, this one
is always deselected when new data is imported.
-
Align to the standard
-
If this is selected, the data are aligned to the specified
standard using the auto-alignment algorithm. If both
the data and standard have reference channels, those are used in
the auto-alignment.
-
Set parameters to the standard
-
If this is selected, all parameters (except for
«eshift») will be
set to the values of the standard.
The pre-processing tab is one of ATHENA's genuine power
features. With a bit of forethought, most of your data processing can
be performed automatically. I typically import one data file and
carefully calibrate it and set its various parameters. Having done
that, the remaining data gets well processed simply by reading it in.
This kind of time saver is of particular value at the beam line.
![[Athena logo]](../../images/pallas_athene_thumb.jpg)