8.2. Project files¶
The most important type of output file is the project file. A project file contains all of the data you have imported, all of the parameters associated with each data file, the content of the journal, and several other collections of important data. All of this gets saved in a single, easily transportable file.
The primary purpose of the project file is to save you work. When you open a saved project file, all of the data and all of their parameters are imported into ATHENA, returning ATHENA to the state it was in when saved the project file. ARTEMIS (ATHENA's sister program intended for analysis of EXAFS data) can read these project files. Thus the project file is the best way of moving your data between the two programs.
Even better, the project file is a form of collaboration. The format of the file is platform independent. A project file written on one computer can read on another computer, even if those computers use different operating systems. A project file can be burned to a CD, placed on a web site, or sent to a collaborator by email.
To save a project file, simply select one of the File menu options highlighted in this figure.
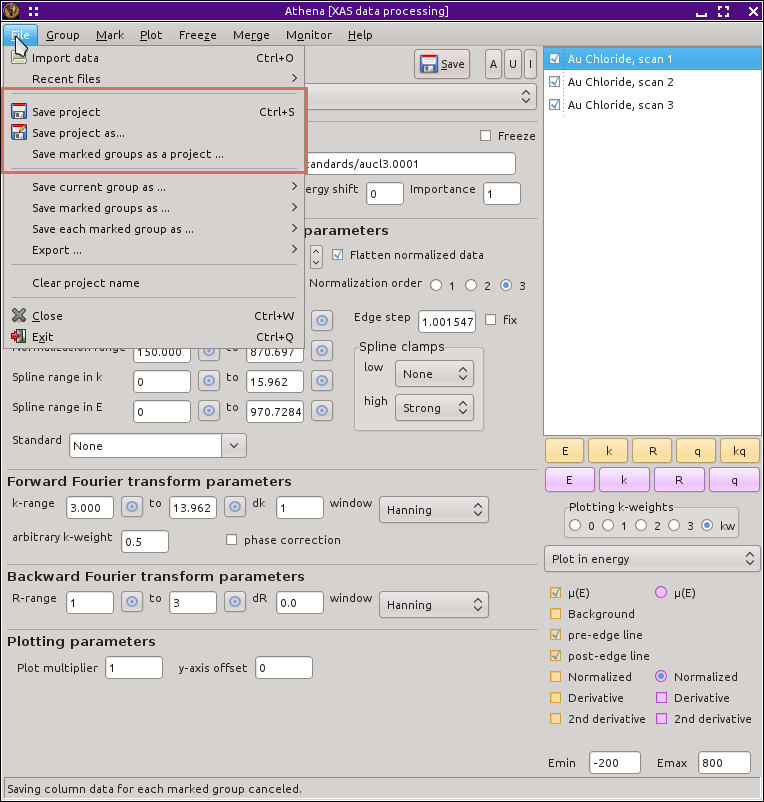
Fig. 8.4 Saving a project file.
The first two options saves the entire current state of ATHENA. If the project has already been saved, the Save project option overwrites the previous file with the new state of your project. Hitting Control-s does the same thing. Alternately, you can select Save project as... and you will be prompted for a new file name for the project.
The final option will write only the marked groups to a project file. You can think of this as a sort of “sub-project” file. This is another of the many ways that the group markings are used by ATHENA.
The Save button at the top of the screen is another way to save the current project, prompting for a file name if needed. As you work with ATHENA. this button turns increasingly red, reminding you of the need to save your work early and often.
Caution
As with any software, you should save your work early and often. ATHENA and IFEFFIT have their flaws. It would be a shame to discover one of them after having done a lot of unsaved work.
8.2.1. The nagging button¶
At the top of the main window is a Save button that serves the same purpose as selecting . As you work with ATHENA, this button will slowly change color, becoming a brighter and brighter shade of red. This is a reminder that you should save your project file. Once you save the project, the button is restored to its original color.
The pace at which the Save button turns red is controlled by the ♦Athena→save_alert configuration parameter. Setting this to a smaller number will make the button turn red faster, larger will make it turn slower. Setting it to 0 will turn the nagging feature off entirely.
8.2.2. The project file format and compatibility with older versions¶
The ATHENA project file is designed to be quick and easy for ATHENA to read. Unfortunately, the file format is not particularly human-friendly. Most of the lines of the project file are in the form written out by perl's Data::Dumper module. This freezes ATHENA's internal data structures into perl code. When the project file is imported, these lines of perl code are evaluated. (This evaluation is performed in a Safe compartment, i.e. a memory space with restricted access to perl's system functionality. This provides a certain level of protection against project files constructed with malicious intent.)
The project file is written using compression in the format of the
popular gzip program using the highest
level of compression, albeit without the common .gz file
extension. Both ATHENA and ARTEMIS use these
files.
8.2.3. Saving state of analysis tools¶
New in version 0.9.25: The states of the LCF, PCA, and peak fitting tools are now saved in the project file. These states will be restored from a project file if (and only if) the entire project file is imported. Importing only a subset of the groups in the project file will fail to trigger the import of the analysis states.
In the original format, these are additional Data::Dumper strings written to the project file. These lines should be silently ignored by earlier versions of DEMETER.
In the JSON format (see below), they are written just prior to the
_____journal line and have these descriptive keys in the JSON
dictionary: _____lcf, _____pca, and _____peakfit. The
lineshape objects used by the peak fitting tool have keys like
_____lineshape0, _____lineshape1, and so on.
8.2.4. The new JSON-style project file¶
New in version 0.9.21: A new feature in ATHENA allows one to write project files in the form of a compressed JSON file. That is, the data that are compressed can be interpreted by any JSON parser. Thus, if you want to use some other language to handle data processed by ATHENA and you want a good pipeline from ATHENA into your code, you could save your project file in the new, JSON format. See the ♦Athena→project_format configuration parameter.
Note, however, that this project file format is entirely incompatible with earlier versions of ATHENA. Versions since 0.9.21 will recognize and read the JSON-style project file regardless of the value of ♦Athena→project_format.
8.2.4.1. Summary¶
- JSON-style project file is valid JSON, possibly gzipped
- File contains a single dictionary
- An entry with the key
_____header1contains the string and is in the first four lines of the file. This is used by DEMETER to recognize the project file. - An entry with the key
_____ordertakes a list of strings as its value. This is used to presevre the order of presentation of the data regardless of how a JSON parser orders the keys in the dictionary. - Data groups use a group name as the key and take a dictionary as
the value. This dictionary contains a key called
argswhich takes a dictionary of attributes and values, a keyxcalled with a vlue of a list containing the abscissa array, and a keyycalled with a value of a list containing the abscissa array. Other optional arrays are possible. - Every data group has a unique group name used as its dictionary key.
- The
argsdictionary has several required attributes, includingdatatype, which is used to interpret the content ofxandy. - Other data processing attributes can be specified in
argsor ATHENA can be relied upon to set sensible defaults. - A project journal is optionally specified with the key
_____journaland a list of strings containing the jounral text. - State of the LCF, PCA, and Peak Fit analysis tools are optionally
saved with keys
_____lcf,_____pca, and_____peakfitwith the lineshape objects used in peak fitting saved as_____lineshape0,_____lineshape1, and so on.
8.2.4.2. Fields in the JSON file¶
The JSON-style project file is typically saved as a gzipped file with
a .prj extension. ATHENA/ARTEMIS are able to
read the file gzipped or as plain text. That is, an external
application can save an ATHENA project file with or without
compression.
The project file is a single serialized dictionary. (I'll use pythonic language in this document. By dictionary, I mean what another language might call a hash or an associative array.) Each entry has a key and a value. The value is typically a dictionary or a list.
There are several special fields that the JSON-style project file must contain so that ATHENA can properly process the file and preserve the order of display of the data contained in the file.
Special fields all begin with 5 underscores. That's a bit wacky, but 5 preceeding underscores is unlikely to carry special meaning in any programming language, yet underscores are likely to be valid characters for variable or dictionary key names in most languages.
8.2.4.3. Headers¶
Standard JSON does not have comments, so special headers are used to carry material that might have gone into comments.
The first several lines should look something like this
{"_____emacs_mode": "-*- mode: json; truncate-lines: t -*-",
"_____header1": "# Athena project file -- Demeter version 0.9.21",
"_____header2": "# This file created at 2015-02-04T17:23:22",
"_____header3": "# Using Demeter 0.9.21 with perl 5.018002 and using Larch 0.9.24 on linux",
The _____emacs_mode line is a convenience for Bruce. That will
cause the file to display in a helpful way in Emacs, which will help
him troubleshoot problems. That line is not required, but Bruce
will be grateful if you include it.
The _____headerN lines identify the file as an ATHENA
project file, identify the moment of creation, and identify the
program that and computing environment that did the creating.
The _____header1 line is required and it must appear in
the first four lines of the file or
ATHENA/ARTEMIS will not recognize the file as a
project file. In fact, DEMETER tries to match this regexp
in the first four lines:
m{_____header\d.+Athena project file}
This regexp is insensitive to the type of quote or the amount of
whitespace. The index N in _____headerN is not important. But one
of the header fields must contain the string Athena project
file and must show up in the first four lines of the file.
The _____header2 and _____header3 lines are recommended,
including them is good form and may help with troubleshooting. It is
recommended that _____header2 use an ISO 8601
combined date and time timestamp. It is recommended that
_____header3 clearly identify the tool that wrote the file. That
said, those two headers are not used in any way by ATHENA
or ARTEMIS.
8.2.4.4. Other fields¶
There must be a field called _____order which is a list of
group names in the order of display. Because the decoded JSON file is
a dictionary, the order of entries cannot be guaranteed once
decoded. The ATHENA user expects to see the data in the
same order when a project file is re-opened. , then, is used to
specify the order.
Here is an example from a project file with two data groups:
"_____order": ["ftaja","cyrlv"]
A field called _____journal is optional. If provided, it is a list
of strings that together are user-supplied commentary on the project
file. In the context of ATHENA, this is the content of the
project journal.
8.2.4.5. Data fields¶
A data field has a key which is used as the DEMETER group attribute, the IFEFFIT group name, and the LARCH group name. In the LARCH context, a data group might be defined like so:
ftaja = read_ascii('mydata.dat')
while in the IFEFFIT context
read_data(file=mydata.dat, type=raw, group=ftaja)
In each case, “ftaja” is the group name which should be used as the key for the data field. In DEMETER, “ftaja” will be the return value of
$data_object->group;
Each data field consists of a dictionary of attributes, and 2 or more lists of numbers representing data arrays associated with the group.
| subfield name | purpose | required |
|---|---|---|
| args | attribute dictionary | yes |
| x | abscissa array (energy or k) | yes |
| y | ordinate array (μ(E) or χ(k)) | yes |
| i0 | i0 array | no |
| signal | signal array | no |
| stddev | standard deviation array | no |
| xdi | metadata dictionary | no |
ATHENA figures out whether to interpret x and y as
energy/μor k/χbased on the value of the attribute from the
args dictionary.
Here's an example of a data field for a group named “ftaja”. (ATHENA uses, but does not require, random 5-character strings as group names.)
"ftaja": {
"args": {"key1": "val1", ..., "keyN": "valN"},
"x": ["6911.98862","6916.99353", ...],
"y": ["0.044142489773191296","0.041334046117570016", ...],
"i0": ["41410.4","41396.4", ...],
"signal": ["39622.2","39720.2", ...]
}
A proper JSON parser is used to read the project file. The content must be valid JSON, but can be linted in any way. ATHENA writes the data subfields as single lines, but that is not required.
8.2.4.6. Attributes¶
The following tables explain all the attributes found in a project file written by ATHENA. They are all listed here for the sake of completeness and to document the contents of an ATHENA-written ATHENA project file.
Every input parameter has a sensible default, thus any or all of these can be skipped in a project file written outside of ATHENA. ATHENA will do the right thing with any that are missing.
For example, a project file can have only parameters related to AUTOBK. Those will be used by ATHENA and ATHENA's defaults will be used elsewhere.
Attributes described with things like output, determined from data, or user-supplied can be ignored by an external application writing a project file. Those attributes are either evaluated by ATHENA during normal operation or can safely be ignored.
The lexicon of attribute names is open for discussion. The
ATHENA project file is basically a serialization of
DEMETER Data objects and the keys of the args
dictionary are the attribute names used by that object.
The object system used by DEMETER has a convenient aliasing system for symbol names. It will be sufficiently easy for DEMETER to be retrofitted to use a different lexicon.
8.2.4.7. Essential attributes¶
A data entry in the project file cannot be considered complete without
these attributes included in the args dictionary.
| attribute name | description | options |
|---|---|---|
| datatype | identify the type of data contained in the data entry | xmu, xanes, chi, xmudat |
| group | string used as the group name | Athena uses random 5-character strings |
| label | string used as a label, for example in Athena's group list | default is the file name |
| is_nor | flag indicating μ(E) data is already normalized | false |
I suppose that group is not necessary since the same string is
used as the key. Hmmm....
Note that the label need not be unique, but the name must
be.
8.2.4.8. Background removal attributes¶
| attribute name | description | DEMETER's default |
|---|---|---|
| bkg_algorithm | autobk or cl | autobk (cl not currently available) |
| bkg_cl | not currently used | |
| bkg_clamp1 | lower clamp value | 0 |
| bkg_clamp2 | upper clamp value | 24 |
| bkg_deltaeshift | uncertainty in fitted energy shift | 0 |
| bkg_dk | sill width for autobk Fourier transform | 1 |
| bkg_e0 | edge position in eV | determined from data |
| bkg_e0fraction | fraction used in Athena's edge fraction algorithm | 0.5 |
| bkg_eshift | energy shift for alignment or calibration | 0 |
| bkg_fittedstep | determined value for edge step | determined from data |
| bkg_fixstep | flag to fix edge step to user-supplied value | false |
| bkg_flatten | flag to plot "flattened" data | true |
| bkg_fnorm | flag to do functional normalization | false |
| bkg_formere0 | saved value of e0 when changing its value | |
| bkg_int | intercept of pre-edge line | determined from data |
| bkg_kw | k-weight used in autobk Fourier transform | 1 |
| bkg_kwindow | functional form of window for autobk FT | hanning |
| bkg_nc0 | post-edge polynomial constant parameter | determined from data |
| bkg_nc1 | post-edge polynomial linear parameter | determined from data |
| bkg_nc2 | post-edge polynomial quadratic parameter | determined from data |
| bkg_nc3 | post-edge polynomial quartic parameter | determined from data |
| bkg_nclamp | number of data points used in clamp | 5 |
| bkg_nnorm | normalization order (1,2,3) | 3 (2 for XANES data) |
| bkg_nor1 | lower bound of post-edge region | 150 above edge |
| bkg_nor2 | upper bound of post-edge region | 100 volts from end of data |
| bkg_pre1 | lower bound of pre-edge region | -150 from edge |
| bkg_pre2 | upper bound of pre-edge region | -30 from edge |
| bkg_rbkg | autobk Rbkg value | 1 |
| bkg_slope | slope of pre-edge line | determined from data |
| bkg_spl1 | lower bound of autobk spline in k | 0 |
| bkg_spl1e | lower bound of autobk spline in energy | 0 (relative to edge) |
| bkg_spl2 | upper bound of autobk spline in k | end of data |
| bkg_spl2e | upper bound of autobk spline in energy | end of data |
| bkg_stan | group used as background removal standard | none |
| bkg_step | edge step | determined from data or user-supplied |
| bkg_tiee0 | unused | |
| bkg_z | 1- or 2-letter symbol of absorber | determined from data |
| nknots | number of knots used in Autobk | determined from bkg parameters |
| referencegroup | group name of group used as background standard | none |
8.2.4.9. Forward transform parameters¶
| attribute name | description | DEMETER's default |
|---|---|---|
| fft_edge | absorption edge of measurement | determined from data |
| fft_kmin | lower end of trasnform range | 3 |
| fft_kmax | upper end of trasnform range | 2 inv Ang from end of data |
| fft_kwindow | functional form of window | hanning |
| fft_dk | window sill width | 2 |
| fft_pctype | phase correction type ('central' or 'path') | central |
| fft_pc | flag for phase corrected transform | false |
| fft_pcpathgroup | path to use for phase corrected transform | none |
| rmax_out | maximum value of R grid | 10 |
8.2.4.10. Backward transform parameters¶
| attribute name | description | DEMETER's default |
|---|---|---|
| bft_rmin | lower end of backtransform/fitting range | 1 |
| bft_rmax | upper end of backtransform/fitting range | 3 |
| bft_dr | window sill width | 0 |
| bft_rwindow | functional form of window | hanning |
Note that the fitting range in ARTEMIS is the back-transform range in ATHENA and uses the same attributes.
8.2.4.11. Fitting parameters¶
| attribute name | description | DEMETER's default |
|---|---|---|
| fit_k1 | flag to use k=1 weighting in fit | true |
| fit_k2 | flag to use k=2 weighting in fit | true |
| fit_k3 | flag to use k=3 weighting in fit | true |
| fit_karb | flag to use user-supplied k weighting in fit | false |
| fit_karbvalue | user-supplied k-weighting | 0.5 |
| fit_space | space in which to evaluate fit (k, R, q) | R |
| fit_epsilon | measurement uncertainty | 0 (i.e. use LARCH's estimate) |
| fit_cormin | smallest correlation to report in log file | 0.4 |
| fit_include | flag to include this data set in a fit | true |
| fit_data | data count in a multiple data set fit | set at time of fit |
| fit_plotafterfit | flag for pushing data to Artemis' plot list after fit finishes | true for first data set in project |
| fit_dobkg | flag for background corefinement | false |
| fit_rfactor1 | R-factor computed with k-weight = 1 | output |
| fit_rfactor2 | R-factor computed with k-weight = 2 | output |
| fit_rfactor3 | R-factor computed with k-weight = 3 | output |
| fit_group | pointer to the fit group that this data is a part of | set at time of fit |
Note that the fitting range in ARTEMIS is the back-transform range in ATHENA and uses the same attributes.
8.2.4.12. Plotting parameters¶
| attribute name | description | DEMETER's default |
|---|---|---|
| plot_scale | multiplier used when plotting data | 1 |
| plot_yoffset | vertical offset used when plotting data | 0 |
| plotspaces | string explaining how a data group can be plotted | determined from datatype attribute |
8.2.4.14. Other data processing parameters¶
Again, these are all things that an external program is unlikely to need to specify.
| attribute name | description | DEMETER's default |
|---|---|---|
| importance | user-supplied relative merge weight | 1 |
| epsk | measurement uncertainty in k | determined from data |
| epsr | measurement uncertainty in R | determined from data |
| i0_scale | in a plot of data with i0&signal, this scales i0 to the size of the data | determined from data |
| is_col | flag indicating data originated as column data | false |
| is_fit | ??? | |
| is_merge | flag indicating data group was made by merging data | false |
| is_pixel | flag indicating dispersive XAS data | false |
| is_special | ??? | |
| is_xmu | flag indicating μ(E) data (deprecated, but seen in old project files) | true |
| rebinned | flag indicating data group was made by rebinning data | |
| signal_scale | in a plot of data with i0&signal, this scales signal to the size of the data | determined from data |
8.2.4.15. And all the rest¶
Much of this need not be written by an external application. Some of this is chaff. I've been working on ATHENA for a loooong time now....
| attribute name | description | DEMETER's default |
|---|---|---|
| annotation | inherited attribute not used by Data objects | |
| beamline | name of beamline where data was measured (used to autoinsert metadata) | |
| beamline_identified | flag stating whether beamline was identified | false |
| collided | flag set true if a group name collision is identified | false |
| daq | identifies the data acquisition software, used for automated metadata | |
| datagroup | generally the same as group -- serves a real function in Artemis | |
| file | fully resolved name of source file for data | |
| forcekey | flag used to help select correct string for use in plot legend | false |
| from_athena | flag stating whether the data group was imported from a project file | false (set true wehn reading Athena project) |
| from_yaml | flag stating whether the data group was imported from an Artemis project | false (set true wehn reading Artemis project) |
| frozen | deprecated | false |
| generated | flag set true if the data are generated (e.g. a merged group) | false |
| mark | apparently not used for anything | |
| marked | flag stating whether the data group is marked in Athena's group list | false |
| maxk | end of k range of data | determined from data |
| merge_weight | weight used for this data group in a merge | 1 |
| nidp | number of independent points in the data | determined from fft and bft parameters |
| npts | number of points in data | determined from data |
| plotkey | string used in plot legend for data group | determined on the fly |
| prjrecord | string identifying filename and record number of data from a project file | determined from data |
| provenance | a short string explaining where the data group came from | set when data is imported |
| quenched | flag set true if attribute values are to be invarient | false |
| quickmerge | flag indicating a certain merging algorithm is in process | false |
| recommended_kmax | Larch's/Ifeffit's best guess of the best kmax value | determined from data |
| recordtype | string used as a label to explain datattype attribute | determined from data |
| source | redundant with file (?) | |
| tag | usually same as the group attribute | |
| titles | list of title lines taken from source file | empty list |
| trouble | string containing results of Artemis sanity checks on fitting model | empty string |
| tying | flag used to avoid infinite recursion when setting e0 of data and reference | false |
| unreadable | flag indicating data file could not be read | false |
| update_bft | flag indicating need to perform back transform | as needed |
| update_bkg | flag indicating need to perform autobk | as needed |
| update_columns | flag indicating need to construct data from columns | as needed |
| update_data | flag indicating need to read data from file | as needed |
| update_fft | flag indicating need to perform forward transform | as needed |
| update_norm | flag indicating need to perform normalization | as needed |
| xdi_willbecloned | flag used to indicate whether XDI metadata is transfered to derived group | false |
| xdifile | filename when recognized as an XDI file | |
| xmax | used in display of description of data in Athena | beginning of data range |
| xmin | used in display of description of data in Athena | end of data range |
DEMETER is copyright © 2009-2016 Bruce Ravel – This document is copyright © 2016 Bruce Ravel
This document is licensed under The Creative Commons Attribution-ShareAlike License.
If DEMETER and this document are useful to you, please consider supporting The Creative Commons.
